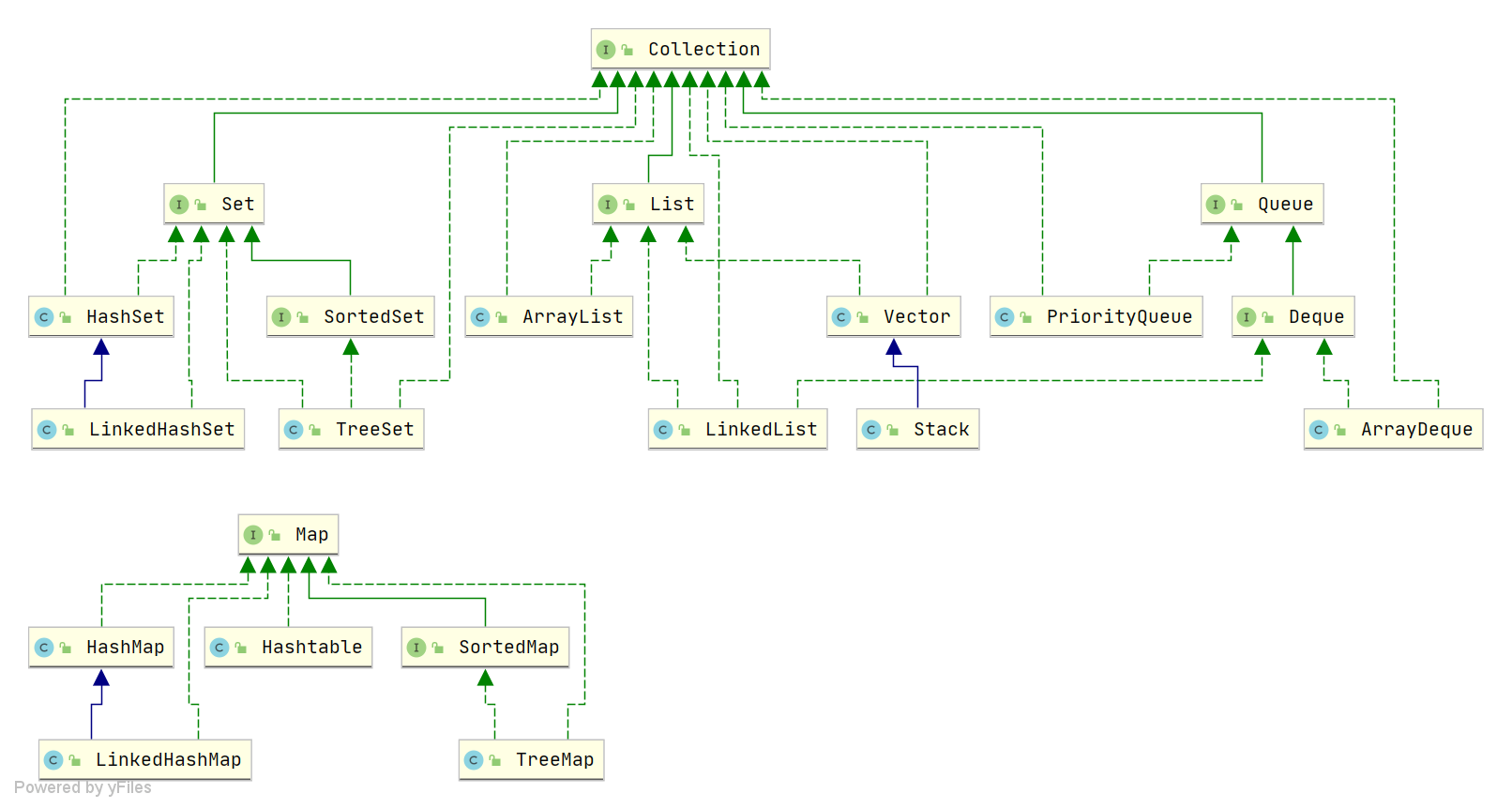
一、什么是Java集合?
Java集合也叫做容器,主要分为两种:
- Collection接口:用于存放单一元素,实现有
Set、List、Queue等 - Map接口:用于存放键值对,实现有
HashMap、LinkedHashMap、Hashtable等
二、List
1、ArrayList和Array有什么区别?
- 扩容:
ArrayList支持动态扩容,Array不支持 - 泛型:
ArrayList支持使用泛型保证数据安全,Array不支持 - 存储对象:
ArrayList只能存储对象(对于基本数据类型只能用其包装类),`Array能存储对象和基本数据类型 - 操作方法:
ArrayList提供add()、remove()等方法,Array不支持 - 大小:
ArrayList创建时不需要指定大小(支持动态扩容),Array创建时需要指定大小(不支持动态扩容)
两者代码实现如下:
public class TestClass {
public static void main(String[] args) {
int[] nums = new int[]{1,2,3};
List<Integer> numList = Arrays.asList(1,2,3);
}
}2、ArrayList和LinkedList有什么区别?
- 底层实现:
ArrayList底层用的是Object[],LinkedList底层用的是双向链表 - 数据安全:
ArrayList和LinkedList都是线程不安全的 - 是否支持快速访问:
ArrayList支持快速访问(实现RandomAccess接口,可通过get(index)方法快速获取元素),LinkedList不支持快速访问(因为是链表结构,内存地址不连续,只能通过指针来关联) - 内存占用:
ArrayList需要先申请内存,会导致如果元素没放满而浪费内存的问题。LinkedList是通过链表动态拼接元素的,所以不会存在浪费内存的问题,但是每一个元素要额外存链表指针,单个元素来说消耗内存比ArrayList大 - CRUD时间复杂度:
ArrayList查询快,插入删除慢(最好情况是O(1),最坏情况是O(n))。LinkedList查询慢,插入删除快(最好情况是O(1),最坏情况是O(n))
一般情况下,能用LinkedList的场景都可以用ArrayList,因为LinkedList也不是说适合元素增删的场景,除了链表头和链表尾插入时间复杂度是O(1),其他位置的增删时间复杂度都是O(n)。
二、Set
Set底层其实是通过Map的key来保证数据不重复的
三、Queue
1、什么是PriorityQueue?
PriorityQueue也就是优先队列,支持按照优先级进行元素出队。
2、什么是BlockingQueue?
BlockingQueue也就是阻塞队列,指的是我们取元素时会阻塞到有元素为止。
Java中BlockingQueue的实现类有以下几种
ArrayBlockingQueue:数组实现的有界阻塞队列。支持公平和非公平锁LinkedBlockingQueue:单向链表实现的可选有界阻塞队列。支持公平和非公平锁PriorityBlockingQueue:支持优先级排序的无界阻塞队列。元素必须都实现Comparable或者在构造函数中传入Comparator对象,不能插入null元素SynchronousQueue:同步队列,是一种不存储元素的阻塞队列(插入后阻塞等待消费删除),一般用于线程之间的直接传递数据DelayQueue:延迟队列,元素到了指定的时间才会出队
四、Map
1、HashMap和Hashtable有什么区别?
- 线程安全:
HashMap线程不安全(如果需要安全就用ConcurrentHashMap),Hashtable线程安全(因为方法都加了synchronized同步锁) - 效率:
HashMap效率要比Hashtable快(因为要考虑线程安全的问题) - null值:
HashMap可以支持key和value为null,Hashtable不支持key和value为null - 大小:
HashMap默认大小为16(如果自定义大小,由于设计需要会扩容到2的整数次方大小),每次扩容为之前的2倍,Hashtable默认大小为11,每次扩容为之前的2n+1倍 - 底层实现:
HashMap是通过数组+链表的方式实现(JDK 8之后链表会在超过阈值时转为红黑树),Hashtable只是通过数组+链表的方式实现
2、HashMap为什么要用2的整数次方作为大小?
目的是让哈希更加分散,尽量减少碰撞。
问题:Hash值的取值范围是-2147483648到2147483648,这么大的取值范围用来做散列值按理说是很难出现碰撞的,但是我们也不可能把这么一个40亿长度的数组放入内存里。
解决方案:先根据数组长度做取模,也就是计算Hash值到数组长度范围内,具体计算方法为hash%n(n代表数组长度)
具体为什么是用2作为幂次方呢?:因为正常的取模运算hash%n性能会比较差,但如果用位运算就会快很多。如果用2作为幂次方,那么hash%n == (n-1) & hash,就会极大提升计算性能
//TODO 具体单独出篇文章解析源码
3、HashMap底层实现
//TODO 具体单独出篇文章解析源码
4、HashMap扩容导致的死循环问题(线程不安全)
//TODO
5、ConcurrentHashMap如何保证线程安全?和Hashtable有什么区别?
//TODO
