一、什么是Redis集群?
具体可参考文章《Redis集群》
二、什么是脑裂问题?
脑裂通俗来说就是大脑裂开了,在Redis集群中指的是有多个集群子集,每个集群子集都有自己的大脑(即Leader节点),那么就会出现不同大脑之前的数据不一致问题。
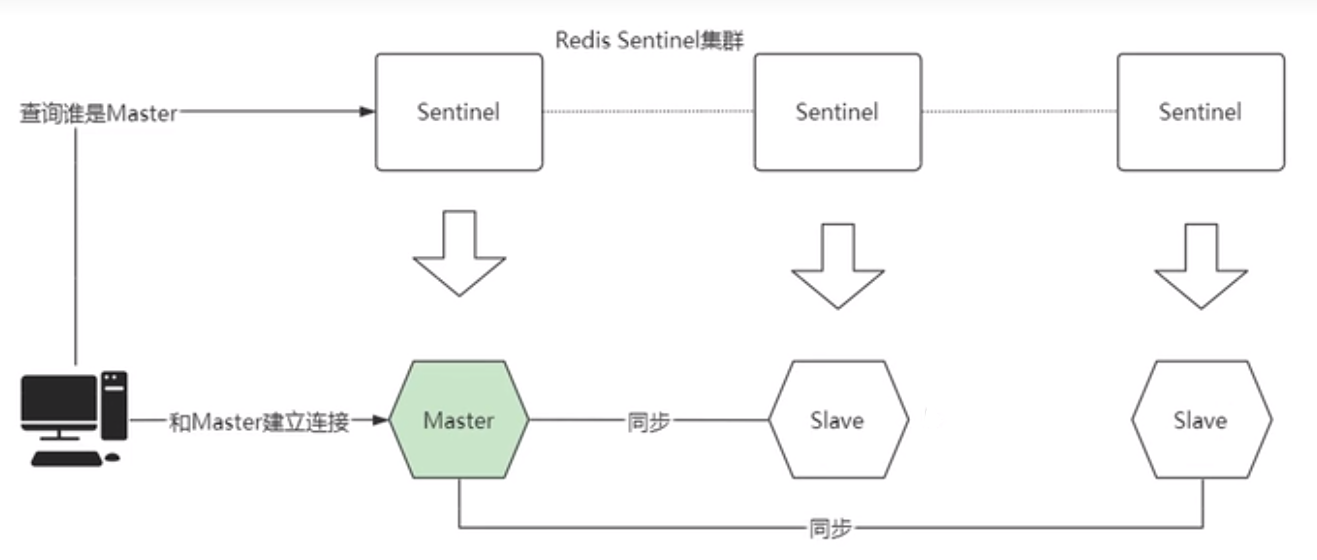
1.默认Master节点监听客户端读写请求,并同步给Slave节点。Sentinel节点负责监控Redis节点状态并做故障转移
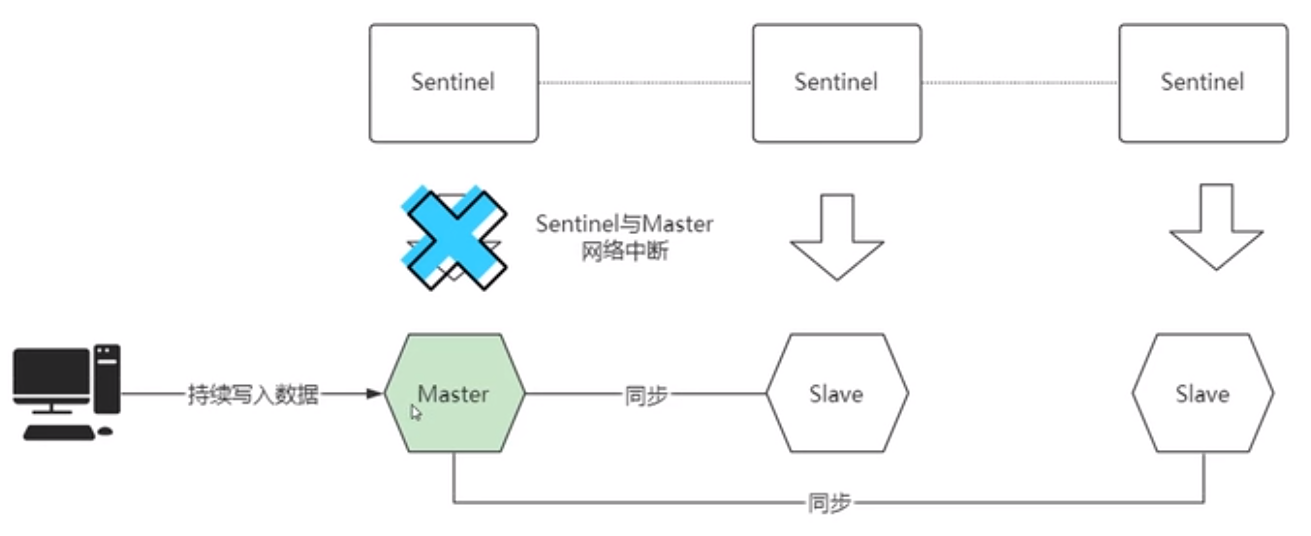
2.当Master节点与Sentinel节点网络中断时,Sentinel节点无法监控Master节点的状态,最后认为其下线
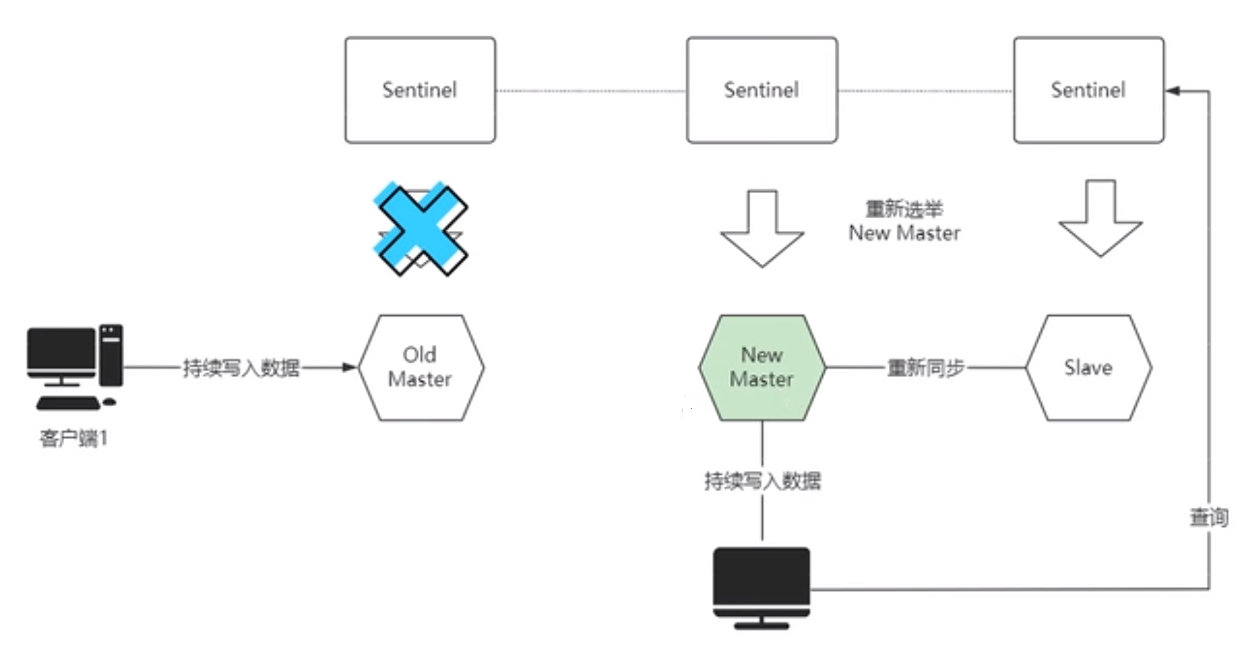
3.这时Sentinel节点会进行故障转移,选举一个Slave节点为新的Master节点(这时候出现脑裂,新老Master节点都会处理客户端读写请求,导致数据不一致问题)
4.突然旧Master节点和Sentinel节点的网络恢复了,并将其设置为Slave节点,重新去新Master节点同步新的数据(全量同步,说明旧Master节点出现脑裂期间的数据变化丢失)
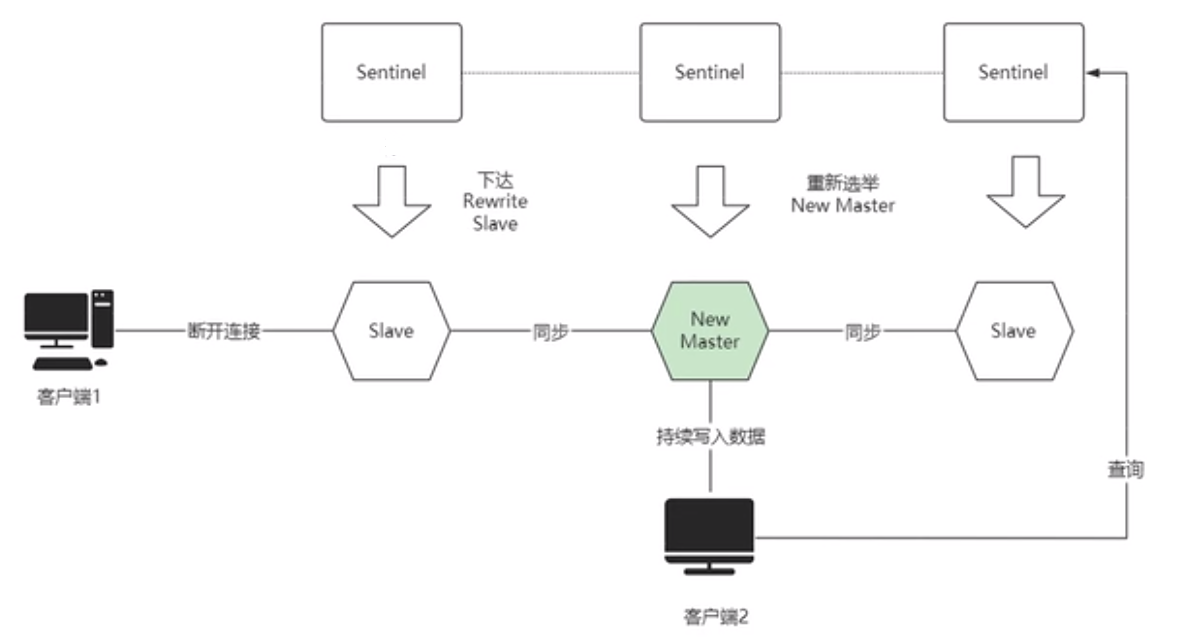
具体数据丢失情况如下,老Master节点恢复网络后称为Slave节点,向新Master节点申请全量数据,并覆盖当前RDB(说明老Master节点在脑裂期间的数据变化丢失)
三、如何解决脑裂问题?
对于脑裂问题,我们可以通过设置两个参数来减少问题的发生,具体如下:
min-replicas-to-write=1:表示Master节点写入的Slave节点至少为1时,才允许接收新的写请求(像上面的例子,当出现脑裂的时候,老Master节点不存在Slave节点,所以不会接受新的写请求,所以不会出现数据不一致问题)min-replicas-max-lag=10:表示Master节点在最多10秒都没得到Slave节点的响应,则认为该Master节点不可用,并会暂停该Master节点新的写请求
这两个配置是满足其中一个即可吗?:需要同时满足
这种解决方案有什么缺点呢?:会降低Redis服务的可用性,如果Slave节点都挂了,那么Master节点将停止接受新的写请求
能彻底解决脑裂问题吗?:并不能,只能说降低丢失的可能性。比如说在min-replicas-max-lag秒内出现了写请求,但是并没有得到Slave节点的响应,那么重新选举之后就会丢失min-replicas-max-lag秒内新接受的写请求数据

