一、排行榜的最佳实践
1、实现方式
一般情况下,排行榜可以通过MySQL或者Redis来做实现,但在特定场景下也可以用大数据来做数据支持,那么不同实现方式有什么区别呢?:
| 排序方式 | 优点 | 缺点 | 适用场景 | |
|---|---|---|---|---|
| MySQL | order by | 数据可靠性较高 | 性能较差 | 充值、消费榜单等 |
| Redis(常用) | zset | 性能较好 | 数据容易丢失(需要定期落库) | 点赞、签到排行榜等 |
| 大数据 | 能够计算多维度数据 | 实时性不高、实现较复杂 | 电商商品推荐榜单等 |
2、存储设计
一般情况下,我们都会选择Redis的zset数据结构来实现一个排行榜,但是如果榜单数据量过大的话,那么用单key是难以支撑的。
那么我们可以用分桶的思想,将排行榜按照积分拆分为多个zset,如图所示: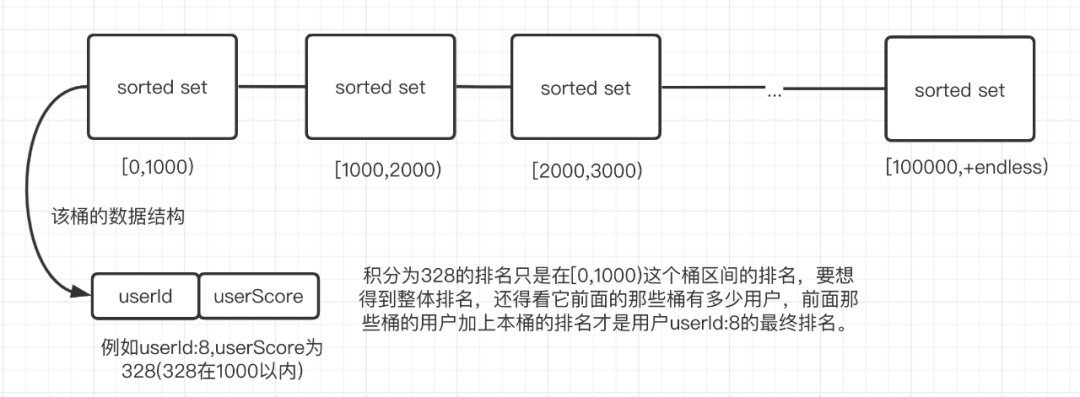
优点:避免单key过大,能有效加快读写性能
缺点:实现复杂,要考虑分数增加带来的桶升级(不建议数据量小的场景去使用)
3、多维度排序
一般情况下,我们都会选择Redis的zset数据结构来实现一个排行榜,但是zset只支持一个score字段给我们使用,那是不是就只能单维度排序了呢?
比如我们在积分相等的时候,按照先达成的排前面,那么就可以把时间信息存到小数点后(前提是分数只有正整数),查询分数的时候直接拿正数部分即可(具体可参考文章《如何实现一个分数相同则按时间排序的排行榜?》)。
但如果我们不止时间维度,还可能有性别维度、点赞维度等呢?那么我们可以参考雪花算法,来将score分为多个段,每个段存不同的维度积分,再按照先后优先级排序即可(具体可参考文章《如何设计分布式ID?》)
4、分页查询
我们的印象中,比如我们的点赞排行榜、商品排行榜、消费排行榜等,都好像不是全量查询的?没错,一方面是为了查询性能,避免一次性查询大量数据,另一方面也是场景限制,一般我们的排行榜只需要显示Top10、Top100等,最多再加上当前用户的排名即可。
所以,我们在功能设计上,一般就默认分页查询即可,一页10条20条都可以,但是为了防止深分页问题的出现,我们也要在查询入口处加上参数校验(事实上比如线上请求第1000000条数据,按照功能场景来说是几乎不会也不可能上拉刷新到这么后面去的,所以大概率是用户恶意请求,可以做一下拦截过滤)。
5、适当使用缓存
一些数据实时性不高的排行榜我们也可以适当使用缓存,比如服务端缓存、客户端缓存等。
比如微信步数排行榜就比较特殊,每个用户见到的排行榜都是不一样的,如果让我去实现的话,我会分为以下几个步骤:
- 请求当前用户好友列表
- 批量查询好友列表的分数
但实际上,微信步数排行榜除了这些,还有点赞数,而且我们可以发现它的分数并不是实时更新的,所以如果让我去实现的话,我会分为以下几个步骤:
- 请求当前用户好友列表
- 批量查询好友列表的分数+点赞(点赞数可以存到score的小数点处)
- 缓存到客户端本地
- 惰性更新+定时更新(可能会出现一分钟内的数据延迟)
6、定期数据清理
比如我们有一个日榜,那么我们就可以只保留最近3天/7天的数据即可,再前的数据已经没有使用价值了(但如果需要追溯,还是得做好数据落库备份)。
7、热点排行榜二级榜单
正常情况下,如果排行榜有100w个用户,但是使用场景只需要查询前100,这样的话就会出现大量无用的数据了。
所以我们可以结合前面第2步提高的分桶设计,将1100名、101200名…的用户分别放在一个桶里。或者可以在积分分桶的基础上构建一个Top100的二级榜单,大概步骤如下:
- 累加分数,判断是否需要做桶升级
- 重新在最高积分桶中去查询Top100用户+积分(如果单个积分桶不足100则遍历补齐)
- 使用步骤2中的Top100用户+积分构建一个Top100二级榜单
8、数据准确性
在高并发环境下,我们也有必要通过Redis的事务、管道、分布式锁来避免并发写入导致的数据不一致。

